 Tweet
Tweet
Nguyên văn bởi lntran
Xem bài viết
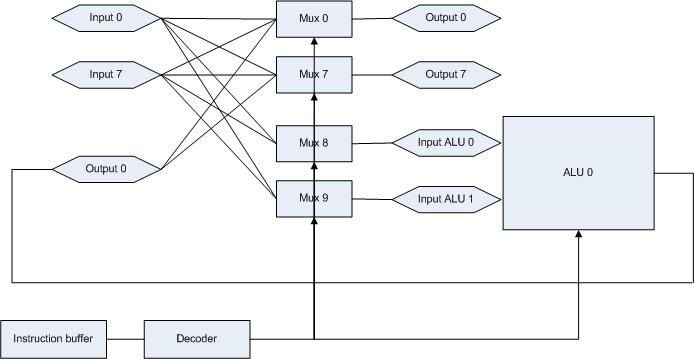
Cảm ơn bác đã giới thiệu sách tham khảo hay. Background của em là analog, lại làm chuyên về power, nên toàn phải dùng kỹ thuật rất cũ bác ạ. Em khoái chỉnh kích thước mosfet rồi soi layout, sau đó nghịch silicon để debug. Gần đây phải đụng digital là bất đắc dĩ thôi, nhưng thấy mỗi cái đều có cái hay riêng. Ví dụ em làm một bộ lọc notch nhỏ nhỏ mà tần số cắt chuẩn lắm bác ạ, sướng hơn anh tương tự nhiều, hay như cái cấu trúc điều khiển PI, thích gain bao nhiêu là đúng bấy nhiêu. Còn về uC thì em không phải là chuyên, mới chỉ dừng lại ở mức simulation thôi chứ chưa có silicon out bác ạ. Thiết kế một test chip, mục đích là để xem liệu nhét cả một uC vào một con power thì nó sẽ thế nào (ý tưởng là cho phép người dùng tự thiết kế con power mình muốn, một dạng kiểu tương tự FPGA).
Nếu bác giới thiệu xong phần concept, mà bác còn hứng thì làm luôn cả flow để mọi người biết thêm về desing số bác ạ.
Rất mong.
P/S: mà các bác đã định luộc Mr.Paul chưa đấy ạ, nếu các bác định nhậu thì ới em phát nhá.



Comment